資料重複,一直都是知識管理的一大難題!
這是因為過去的搜尋技術不好找資料 (註),
一旦找不到,
就只好再寫一份,自然就造成知識庫裡面有許多重複內容的問題。
還好有 AI,透過 embeding 的技術就有機會克服!
xms+ AI 更優化這項技術,在使用 AI 的過程中輕鬆發現重複的資料。
怎麼知道重複?
這簡單!「什麼都先問 AI」就對了。
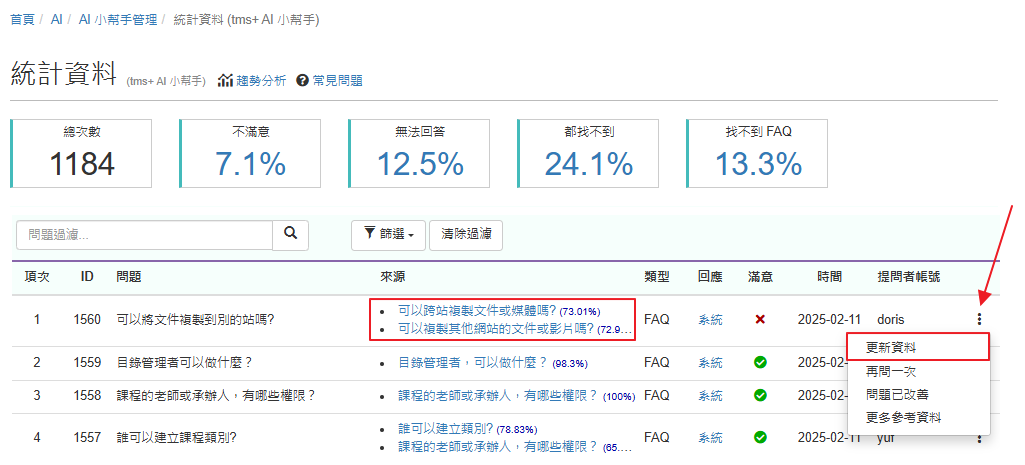
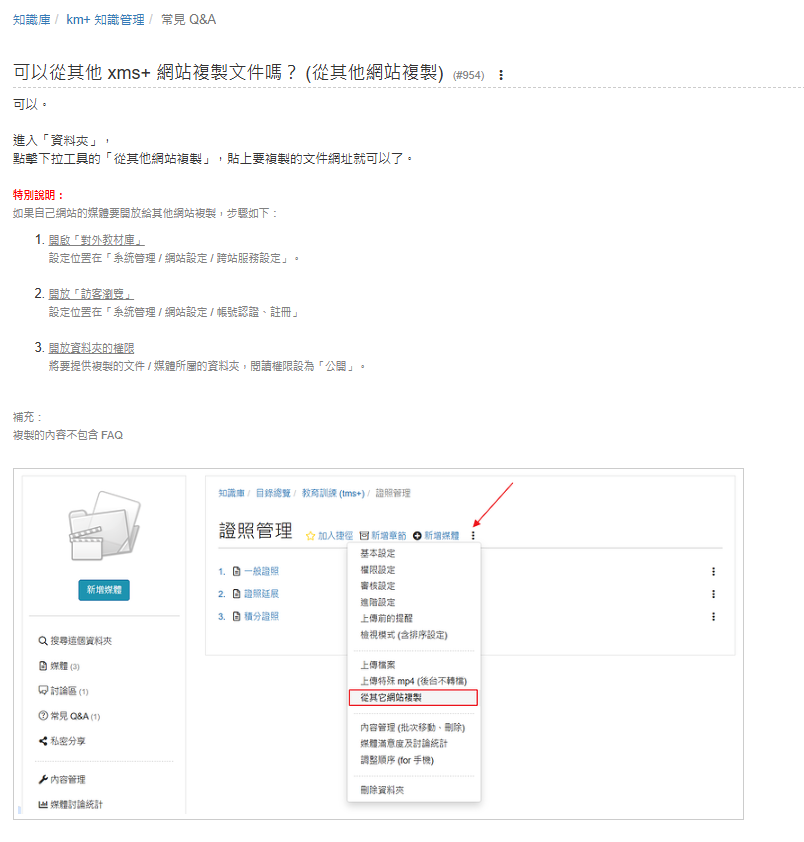
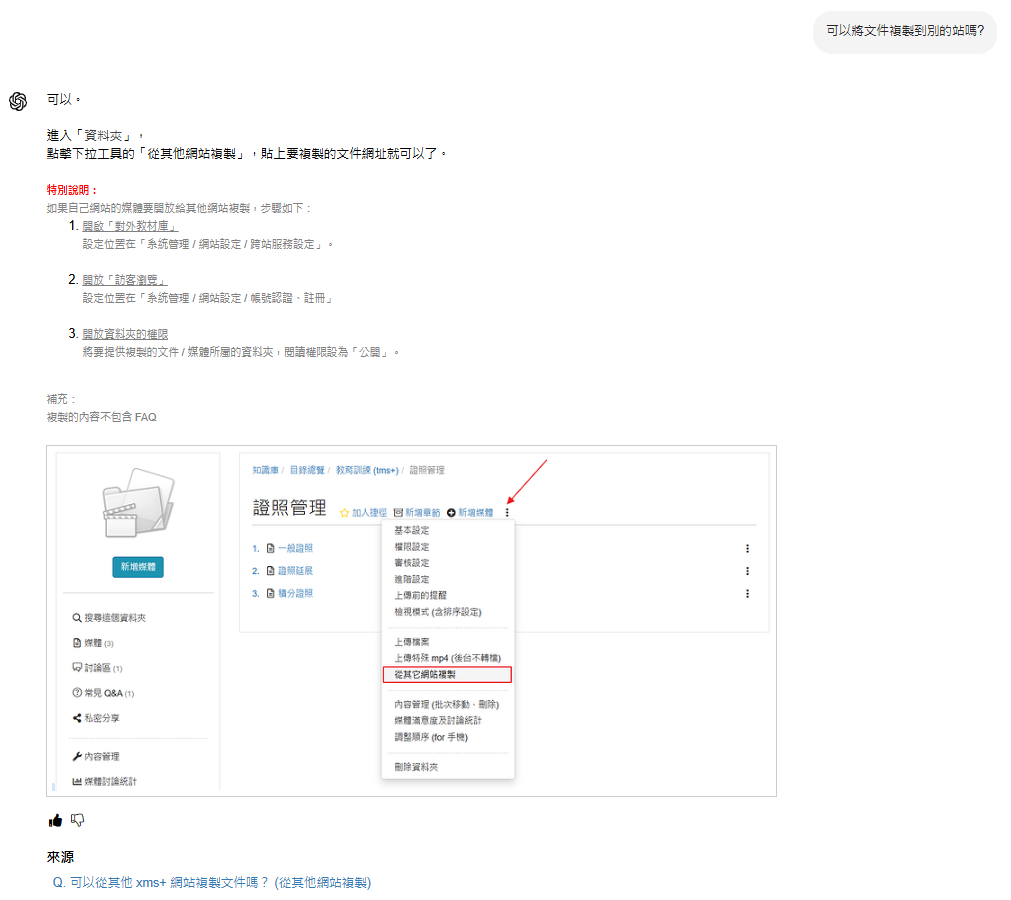
以下圖為例,
AI 除了明確列出兩篇的 FAQ 和使用問題是一樣的之外,
「相關資料」清單也是發現「重複內容」的重要線索。
改善重複的問題
一旦 AI 解決找得到資料的問題
就可以持續改善原內容,不用再重寫一份。
發現重複的資料,就能進行合併 or 刪除。
處理重複的策略,
最直接的方法就是合併,截長補短一下。
如果不好合併呢?那就保留呀
例如:
- 不同的問法 (切入點),就可以保留,增加覆蓋率
- 問法類似,但重點不同
- ...
重複資料的處理,是超級重要的步驟!
因為一旦重複資料,就很容易產生資料不一致的問題,大福降低知識庫的價值。
雖然不容易,但一回生二回熟,
每次練一點,就能把業務化為無痛的習慣喔。
附註:
傳統找資料只能使用「關鍵詞」或「分類」,
因為每個人用的關鍵詞可能不一樣,分類習慣也不同,就很容易發生明明就有資料,但就是「找不到」的問題。